Toil Architecture¶
The following diagram layouts out the software architecture of Toil.

Figure 1: The basic components of Toil’s architecture.¶
- These components are described below:
- the leader:
The leader is responsible for deciding which jobs should be run. To do this it traverses the job graph. Currently this is a single threaded process, but we make aggressive steps to prevent it becoming a bottleneck (see Read-only Leader described below).
- the job-store:
Handles all files shared between the components. Files in the job-store are the means by which the state of the workflow is maintained. Each job is backed by a file in the job store, and atomic updates to this state are used to ensure the workflow can always be resumed upon failure. The job-store can also store all user files, allowing them to be shared between jobs. The job-store is defined by the
AbstractJobStoreclass. Multiple implementations of this class allow Toil to support different back-end file stores, e.g.: S3, network file systems, Google file store, etc.
- workers:
The workers are temporary processes responsible for running jobs, one at a time per worker. Each worker process is invoked with a job argument that it is responsible for running. The worker monitors this job and reports back success or failure to the leader by editing the job’s state in the file-store. If the job defines successor jobs the worker may choose to immediately run them (see Job Chaining below).
- the batch-system:
Responsible for scheduling the jobs given to it by the leader, running a worker command for each job. The batch-system is defined by the
AbstractBatchSystemclass. Toil uses multiple existing batch systems to schedule jobs, including Apache Mesos, GridEngine and a multi-process single node implementation that allows workflows to be run without any of these frameworks. Toil can therefore fairly easily be made to run a workflow using an existing cluster.
- the node provisioner:
Creates worker nodes in which the batch system schedules workers. It is defined by the
AbstractProvisionerclass.
- the statistics and logging monitor:
Monitors logging and statistics produced by the workers and reports them. Uses the job-store to gather this information.
Jobs and JobDescriptions¶
As noted in Job Basics, a job is the atomic unit of work in a Toil workflow.
Workflows extend the Job class to define units of work.
These jobs are pickled and stored in the job-store by the leader, and are retrieved
and un-pickled by the worker when they are scheduled to run.
During scheduling, Toil does not work with the actual Job objects. Instead,
JobDescription objects are used to store all the information
that the Toil Leader ever needs to know about the Job. This includes requirements
information, dependency information, body object to run, worker command to issue, etc.
Internally, the JobDescription object is referenced by its jobStoreID, which is often not human readable. However, the Job and JobDescription objects contain several human-readable names that are useful for logging and identification:
jobName |
Name of the kind of job this is. This may be used in job store IDs and logging. Also used to let the cluster scaler learn a model for how long the job will take. Defaults to the job class’s name if no real user-defined name is available. For a For a CWL workflow, the jobName is the class name of the internal
job that is running the CWL workflow, such as |
unitName |
Name of this instance of this kind of job. If set by the user, it will appear with the jobName in logging. For a CWL workflow, the unitName is the dotted path from the workflow down to the task being run, including numbers for scatter steps. |
displayName |
A human-readable name to identify this particular job instance. Used as an identifier of the job class in the stats report. Defaults to the job class’s name if no real user-defined name is available. For CWL workflows, this includes the jobName and the unitName. |
Statistics and Logging¶
Toil’s statistics and logging system is implemented in a joint class
StatsAndLogging. The class can be instantiated
and run as a thread on the leader, where it polls for new log files in the job
store with the
read_logs() method.
These are JSON files, which contain structured data. Structured log messages
from user Python code, stored under workers.logs_to_leader, from the file
store’s
log_to_leader()
method, will be logged at the appropriate level. The text output that the
worker captured for all its chained jobs, in logs.messages, will be logged
at debug level in the worker’s output. If --writeLogs or
--writeLogsGzip is provided, the received worker logs will also be stored
by the StatsAndLogging thread into per-job files inside the job store, using
writeLogFiles().
Note that the worker only fills this in if running with debug logging on, or if
--writeLogsFromAllJobs is set. Otherwise, logs from successful jobs are not
persisted. Logs from failed jobs are persisted differently; they are written
to the file store, and the log file is made available through
toil.job.JobDescription.getLogFileHandle(). The leader thread retrieves
these logs and calls back into StatsAndLogging
to print or locally save them as appropriate.
The CWL and WDL interpreters use
log_user_stream() to
inject CWL and WDL task-level logs into the stats and logging logging system.
The full text of those logs gets stored in the JSON stats files, and when the
StatsAndLogging thread sees them it reports and saves them, similarly to how it
treats Toil job logs.
To ship the statistics and the non-failed-job logs around, the job store has a
logs mailbox system: the
write_logs() method
deposits a string, and the
read_logs() method on
the leader passes the strings to a callback. It tracks a concept of new and
old, based on whether the string has been read already by anyone, and one can
read only the new values, or all values observed. The stats and logging system
uses this to pass around structured JSON holding both log data and
worker-measured stats, and expects the
StatsAndLogging thread to be the only live
reader.
Optimizations¶
Toil implements lots of optimizations designed for scalability. Here we detail some of the key optimizations.
Read-only leader¶
The leader process is currently implemented as a single thread. Most of the leader’s tasks revolve around processing the state of jobs, each stored as a file within the job-store. To minimise the load on this thread, each worker does as much work as possible to manage the state of the job it is running. As a result, with a couple of minor exceptions, the leader process never needs to write or update the state of a job within the job-store. For example, when a job is complete and has no further successors the responsible worker deletes the job from the job-store, marking it complete. The leader then only has to check for the existence of the file when it receives a signal from the batch-system to know that the job is complete. This off-loading of state management is orthogonal to future parallelization of the leader.
Job chaining¶
The scheduling of successor jobs is partially managed by the worker, reducing the number of individual jobs the leader needs to process. Currently this is very simple: if the there is a single next successor job to run and its resources fit within the resources of the current job and closely match the resources of the current job then the job is run immediately on the worker without returning to the leader. Further extensions of this strategy are possible, but for many workflows which define a series of serial successors (e.g. map sequencing reads, post-process mapped reads, etc.) this pattern is very effective at reducing leader workload.
Preemptable node support¶
Critical to running at large-scale is dealing with intermittent node failures. Toil is therefore designed to always be resumable providing the job-store does not become corrupt. This robustness allows Toil to run on preemptible nodes, which are only available when others are not willing to pay more to use them. Designing workflows that divide into many short individual jobs that can use preemptable nodes allows for workflows to be efficiently scheduled and executed.
Caching¶
Running bioinformatic pipelines often require the passing of large datasets between jobs. Toil caches the results from jobs such that child jobs running on the same node can directly use the same file objects, thereby eliminating the need for an intermediary transfer to the job store. Caching also reduces the burden on the local disks, because multiple jobs can share a single file. The resulting drop in I/O allows pipelines to run faster, and, by the sharing of files, allows users to run more jobs in parallel by reducing overall disk requirements.
To demonstrate the efficiency of caching, we ran an experimental internal pipeline on 3 samples from the TCGA Lung Squamous Carcinoma (LUSC) dataset. The pipeline takes the tumor and normal exome fastqs, and the tumor rna fastq and input, and predicts MHC presented neoepitopes in the patient that are potential targets for T-cell based immunotherapies. The pipeline was run individually on the samples on c3.8xlarge machines on AWS (60GB RAM,600GB SSD storage, 32 cores). The pipeline aligns the data to hg19-based references, predicts MHC haplotypes using PHLAT, calls mutations using 2 callers (MuTect and RADIA) and annotates them using SnpEff, then predicts MHC:peptide binding using the IEDB suite of tools before running an in-house rank boosting algorithm on the final calls.
To optimize time taken, The pipeline is written such that mutations are called on a per-chromosome basis from the whole-exome bams and are merged into a complete vcf. Running mutect in parallel on whole exome bams requires each mutect job to download the complete Tumor and Normal Bams to their working directories – An operation that quickly fills the disk and limits the parallelizability of jobs. The workflow was run in Toil, with and without caching, and Figure 2 shows that the workflow finishes faster in the cached case while using less disk on average than the uncached run. We believe that benefits of caching arising from file transfers will be much higher on magnetic disk-based storage systems as compared to the SSD systems we tested this on.
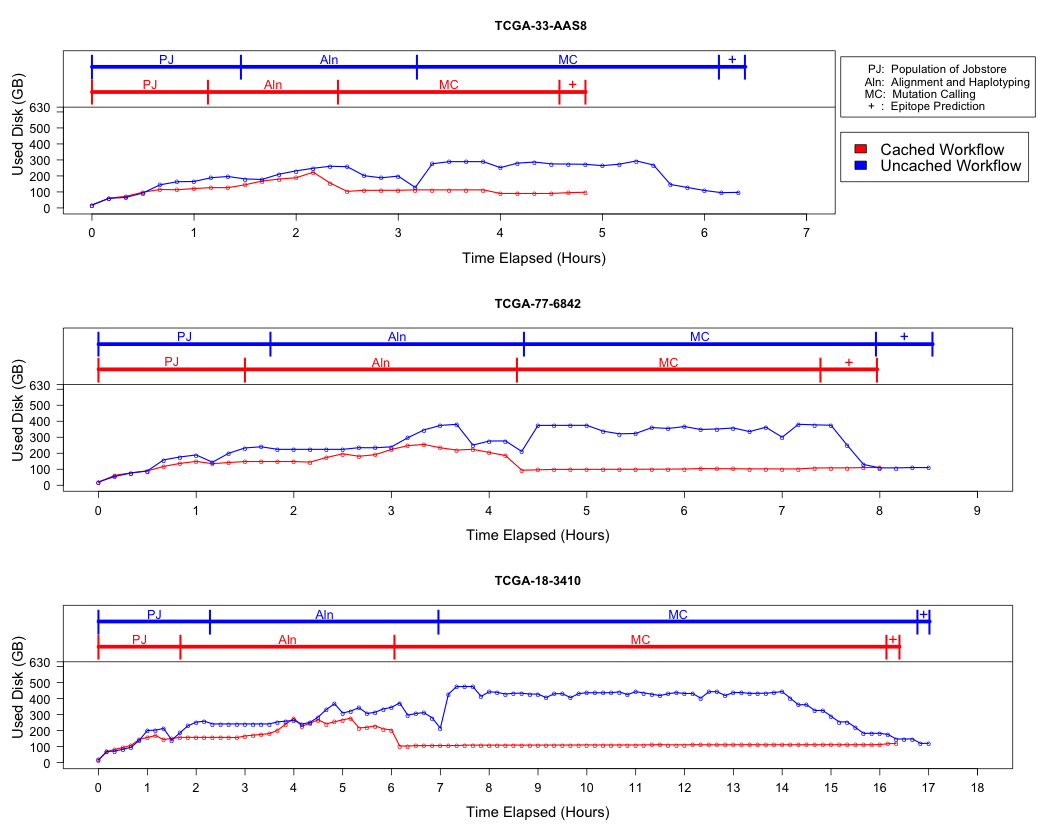
Figure 2: Efficiency gain from caching. The lower half of each plot describes the disk used by the pipeline recorded every 10 minutes over the duration of the pipeline, and the upper half shows the corresponding stage of the pipeline that is being processed. Since jobs requesting the same file shared the same inode, the effective load on the disk is considerably lower than in the uncached case where every job downloads a personal copy of every file it needs. We see that in all cases, the uncached run uses almost 300-400GB more that the cached run in the resource heavy mutation calling step. We also see a benefit in terms of wall time for each stage since we eliminate the time taken for file transfers.¶
Toil support for Common Workflow Language¶
The CWL document and input document are loaded using the ‘cwltool.load_tool’ module. This performs normalization and URI expansion (for example, relative file references are turned into absolute file URIs), validates the document against the CWL schema, initializes Python objects corresponding to major document elements (command line tools, workflows, workflow steps), and performs static type checking that sources and sinks have compatible types.
Input files referenced by the CWL document and input document are imported into the Toil file store. CWL documents may use any URI scheme supported by Toil file store, including local files and object storage.
The ‘location’ field of File references are updated to reflect the import token returned by the Toil file store.
For directory inputs, the directory listing is stored in Directory object. Each individual files is imported into Toil file store.
An initial workflow Job is created from the toplevel CWL document. Then, control passes to the Toil engine which schedules the initial workflow job to run.
When the toplevel workflow job runs, it traverses the CWL workflow and creates a toil job for each step. The dependency graph is expressed by making downstream jobs children of upstream jobs, and initializing the child jobs with an input object containing the promises of output from upstream jobs.
Because Toil jobs have a single output, but CWL permits steps to have multiple output parameters that may feed into multiple other steps, the input to a CWLJob is expressed with an “indirect dictionary”. This is a dictionary of input parameters, where each entry value is a tuple of a promise and a promise key. When the job runs, the indirect dictionary is turned into a concrete input object by resolving each promise into its actual value (which is always a dict), and then looking up the promise key to get the actual value for the the input parameter.
If a workflow step specifies a scatter, then a scatter job is created and connected into the workflow graph as described above. When the scatter step runs, it creates child jobs for each parameterizations of the scatter. A gather job is added as a follow-on to gather the outputs into arrays.
When running a command line tool, it first creates output and temporary directories under the Toil local temp dir. It runs the command line tool using the single_job_executor from CWLTool, providing a Toil-specific constructor for filesystem access, and overriding the default PathMapper to use ToilPathMapper.
The ToilPathMapper keeps track of a file’s symbolic identifier (the Toil FileID), its local path on the host (the value returned by readGlobalFile) and the the location of the file inside the Docker container.
After executing single_job_executor from CWLTool, it gets back the output object and status. If the underlying job failed, raise an exception. Files from the output object are added to the file store using writeGlobalFile and the ‘location’ field of File references are updated to reflect the token returned by the Toil file store.
When the workflow completes, it returns an indirect dictionary linking to the outputs of the job steps that contribute to the final output. This is the value returned by toil.start() or toil.restart(). This is resolved to get the final output object. The files in this object are exported from the file store to ‘outdir’ on the host file system, and the ‘location’ field of File references are updated to reflect the final exported location of the output files.
